Redirect
In this section, we will explore redirecting, appending, piping, and looping with >, >>, |, and for.
If you completed the last challenge, you saw that the images/ directory contains a file called MiSeq-readcount-Mothur.png. This image is a screenshot from the Mothur software tutorial showing the count or number of reads for each sample.
To see if our data matches theirs, we can count the number of lines in the .fastq files with the UNIX command wc. This will print by default the number of characters, words, and lines in a file. We can ask for just the number of lines with the -l option.
cd ~/MiSeq
wc -l *.fastq
This gives something like:
31172 F3D0_S188_L001_R1_001.fastq
31172 F3D0_S188_L001_R2_001.fastq
23832 F3D141_S207_L001_R1_001.fastq
23832 F3D141_S207_L001_R2_001.fastq
...
28280 F3D9_S197_L001_R1_001.fastq
28280 F3D9_S197_L001_R2_001.fastq
19116 Mock_S280_L001_R1_001.fastq
19116 Mock_S280_L001_R2_001.fastq
1218880 total
However, this number is too large. In fact, it is 4 times larger than the number of reads. To capture just the number of reads, we can first use grep followed wc.
By default, many UNIX commands like cat send output to something called
standard out, or "stdout". This is a catch-all phrase for "the basic
place we send regular output." There are also standard error, or "stderr",
which is where errors are printed; and standard input, or "stdin", which
is where input comes from.
Much of the power of the UNIX command line comes from working with
stdout output, and if you work with UNIX a lot, you will see characters
like the > (redirect), >> (append) , and | (pipe) thrown around. These
are redirection commands that say, respectively, "send stdout to a new
file", "append stdout to an existing file", and "send stdout from one
program to another program's stdin". If you know you want to save an output file, you can use the redirect symbol >.
Note, if you want to save a file in a different directory, that directory must exist.
|¶
Let's now use grep to match the first line, which starts with "@M00967", of all the R1 files then pipe the output to wc and count the number of lines.
head -n 1 *.fastq
grep "^@M00967" *R1*.fastq | wc -l
The answer, 152883, matches the authors'. Nice. Also, we just scanned many large files very quickly to confirm a finding.
152883
You probably do not want to read all the lines that were matched, but piping the output to head is a nice way to view the first 10 lines.
grep "^@M00967" *R1*.fastq | head
The result looks like the following. The error message at the end is as expected, and happens after the specified number of lines are printed.
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:18327:1699 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:14069:1827 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:18044:1900 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:13234:1983 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:16780:2259 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:19378:2540 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:17674:2779 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:18089:2781 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:14203:2907 1:N:0:188
F3D0_S188_L001_R1_001.fastq:@M00967:43:000000000-A3JHG:1:1101:19561:3147 1:N:0:188
grep: write error: Broken pipe
To count the number of reads in each file, we could grep each file individually, but that would be prone to errors.
grep "^@M00967" F3D0_S188_L001_R1_001.fastq | wc -l
grep "^@M00967" F3D0_S188_L001_R1_001.fastq | wc -l
grep "^@M00967" F3D142_S208_L001_R1_001.fastq | wc -l
For loops¶
If we want to know how many times it occurs in each in each file, we need a for loop. A for loop looks like this:
for [thing] in [list of things]
do
command $[thing]
done
To answer the question, how many reads are in each R1 file, we can construct the following for loop.
for file in *R1*.fastq
do
echo $file
grep "^@M00967" $file | wc -l
done
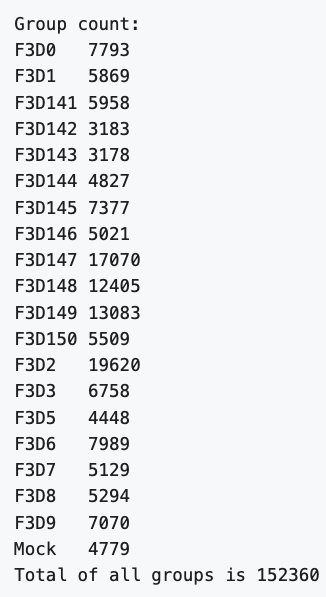
This gives the following result, which matches the authors
F3D0_S188_L001_R1_001.fastq
7793
F3D141_S207_L001_R1_001.fastq
5958
F3D142_S208_L001_R1_001.fastq
3183
...
F3D8_S196_L001_R1_001.fastq
5294
F3D9_S197_L001_R1_001.fastq
7070
Mock_S280_L001_R1_001.fastq
4779
Which eBook contains the most lines that start with "The"?
The following for loop will reveal that 269 lines of A Tale of Two Cities that start with "The".
cd ~/books
for book in *.txt
do
echo $book
grep -w "^The" $book | wc -l
done
Alice_in_wonderland.txt
69
A-tale-of-two-cities.txt
269
book.txt
269
PeterPan.txt
60
WizardOfOz.txt
123
history¶
This lesson focused on file and directory exploration because that is something everyone needs to know, and all these commands will work on pretty much any computer that is running a UNIX compatible shell (including Mac OSX and Windows Subsystem for Linux).
We have shown you multiple options for editing and working with text files. These tools may seem confusing at first, but they will become second nature if you use them regularly.
If you want to save all the commands we used today, you can use the history command to print out all the commands you typed.
history
>¶
You can redirect the output from the screen to a file using >. Note that > will overwrite existing content, but >> will append.
history > ~/history.txt
Key points¶
| Command | Description |
|---|---|
\| |
pipes the standard output to a new command |
> |
redirects the standard output to a new file |
>> |
append the standard output to a new or existing file |
for |
initiates a for loop |